

最近、インパクト評価とかRCTってよく聞くけど、実はよくわかってない・・。従来の評価と何が違うんだろう・・。
最近では国際開発業界でもよく聞かれるようになったインパクト評価およびランダム化比較試験(Randomized Control Trial。通称、RCT)について、統計や経済学を学んだことがない人向けに、なるべくわかりやすく簡単に解説してみたいと思います。
インパクト評価とは??
インパクト評価とは、国際開発プロジェクトや政策などが社会にもたらす効果を精密に(エビデンスをもとに)検証する手法です。インパクト評価の定義は様々あるようなのですが、この記事では、ランダム化比較試験(RCT)を用いたインパクト評価について書いてみます。この評価手法は、これまで国際開発業界では開発経済学者を中心に用いられてきましたが、世界銀行を中心とした国際開発機関やJICAでも使われるようになってきています。
インパクトの定義についてもう少し詳しく知りたいという方はこちらのレポートが参考になると思います。私のこの記事でのインパクトはP2のType III に該当します。
なぜ最近注目を浴びているの?
国際開発プロジェクトや政策などが社会にもたらす効果について、評価者の主観を極力排除し、客観的に評価できるためです。知名度的な大きな転換点としては、2019年のノーベル経済学賞を、インパクト評価を主導してきた開発経済学者が取ったことが大きいです。

JICAが採用している五項目評価とは何が違うの?
国際協力関係者であれば、DAC五項目評価というのを聞いたこと・使ったことがあるかもしれません。JICAの技術協力プロジェクトの評価を中心に、現在でも広く用いられている評価手法で、経済協力開発機構/開発援助委員会(OECD-DAC)が作成した「妥当性・有効性・インパクト・効率性・持続性」という五つの評価軸に沿ってプロジェクトの評価をするというものです。先ほどのレポートでのインパクトの定義(P2)では、Type I またはType II に該当します。

5つの評価軸のうち有効性・インパクトでは、プロジェクトが社会にもたらした効果を表面的に検証することはできるのですが、プロジェクト効果の因果関係は証明できません。例えば、A国の教科書を新しくするというプロジェクトがあったとします。そのプロジェクト前後で小学校卒業率が5%上がったとして、「教科書変えなくても5%上がってたんじゃないの?」とか「それは教科書じゃなくて教育大臣が変わった成果なんじゃないの?」とかいった意地悪な質問をされた場合に反論する証拠は提示できません。
そこに答えるために、因果推論というコンセプトに基づくインパクト評価、つまり、エビデンスに基づいた評価が重要になってきます。
エビデンスとは??
最近いろんなところで「エビデンスに基づく」とか聞きますが、エビデンスとはなんなのでしょう?このインパクト評価で言うところの「エビデンス」というのは、辞書に出てくる「証拠」というよりは「プロジェクトと効果の因果関係(OOの結果、XXになった)を示すデータ」のことと思っていただいた方が良いかと思います。
つまり、インパクト評価とは、新しい教科書のおかげで効果(先ほどの例だと小学校卒業率が5%改善)が本当に出たのかを検証するということになります。そして、そのために使われる手法の一つが、ランダム化比較試験(RCT)になります。
ランダム化比較試験(RCT)とは??
ランダム化比較試験(Randomized Controlled Trial。通称、RCT。)とは、評価対象をランダムに複数のグループに分けて評価することで、プロジェクトと効果の因果関係を特定しようと言う手法です。医療業界では昔から使われていて、試薬と偽薬を異なるグループに投与して効果を検証する時などに用いられています。IT業界でもA/Bテストと呼ばれる似たような手法でページのデザインなどが評価されています。
多分、まだピンとこない方も多いかと思うので、事例を挙げながら説明してみます。
先ほどの例で、A国で教科書改善プロジェクトを実施した結果、小学校卒業率が5%上がったとしましょう。それを聞いて「やった!5%上がった!新しい教科書の成果だぜ!」って言えると思いますか?
そう言いたくなる気持ちはわかるのですが、もしかしたら、教科書を変えていなくても卒業率が5%上がったかもしれません。教科書ではなく教育大臣のイニシアティブのせいかもしれません。もしかすると、教科書を変えなかったら7%上がっていたということもありえるもしれないですよね。一見、屁理屈のように聞こえますが、これらに明確に反論できるデータを示すことができません。なぜなら、ありえない(検証しようがない)話をしているからです。
この因果関係を証明して、反論するための方法はただ一つ、「A国で新しい教科書を使用した場合の結果」と「A国で古い教科書のままだった場合の結果」を同じ時期に同じ場所で比較することなのですが、これタイムマシンでもない限り不可能なわけです。ただ、ここで大事なのは、なぜこれで因果関係が証明できるのかというと、この2つの事象は使用する教科書以外の条件が全て同じだからという点です。
下図は、ここまでの話を図にしたものです。プロジェクトを実施した場合(新しい教科書を使った場合)の結果が「実際に観察される状況」で、(実際には観測できませんが)プロジェクトを実施しなかった場合(古い教科書を使い続けた場合)の結果が「反事実的状況」になります。この図で言うと、プロジェクトの本当の成果は「事業によって引き起こされた変化(事業の効果)」であり、この変化をどうにか測定できれば、因果関係が証明できるわけです。(画像出典:JICA HPより)
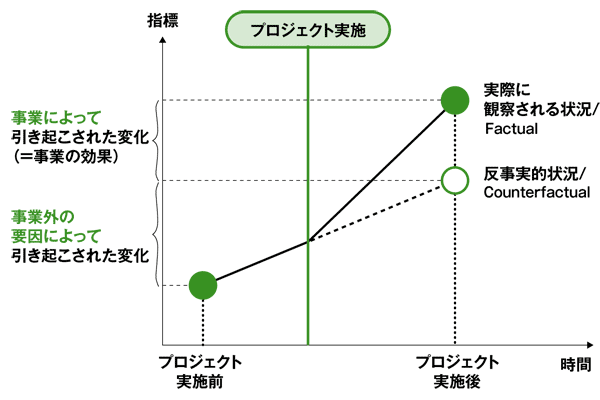
この実際には観測できない反事実的状況を人工的に作り出し、プロジェクトを実施した場合と実施しなかった場合を比較して、プロジェクトの効果を厳密に測定しようとするのがランダム化比較試験(RCT)です。
タイムマシンないのに、そんなことができるの???と思いますよね。でも、それに近いことはできるんです。
具体的には、まず、プロジェクト対象をランダムに(くじ引きのような形で)2つに分けます。例えば、A国にある公立小学校の学区をランダムに2つのグループに分けます。(ここで重要なのはランダムに分けるということで、そのためにランダム化比較試験と呼ばれています)。この2つのグループはランダムに分けているので、ある程度の数(算出には統計学を使います)を確保できれば、平均すると性別・年齢・所得・学力レベル等々はほぼ同等になると言えます。(例えば、A国に学区が1,000あり、それを500ずつランダムに分けたら、各種指標の平均はだいたい同じになりそうですよね?)
以下の図は、ブラジルで自治体をランダムに2つに分けたものです。これはただのイメージ図ですが、「あぁ、確かにこれなら赤と青の各種指標の平均はだいたい同じになりそうだな」と感覚的に思っていただければOKです。(引用:Hjort et al. 2019)
そして、その非常に類似した2つのグループのうち、片方は新しい教科書で、もう片方は古い教科書で、教育をしてもらいます。こうすることで、使用する教科書以外のすべての要素がほぼ同じな2つのグループが作れることになります。この形式で2つのグループを比較すれば、(仮想的ではありますが)他の条件を等しくした状態で、新しい教科書の効果だけを検証することができることになります。
では、この2つのグループでどのくらいの差があったら、新しい教科書の成果で間違いないと言えるのでしょうか?例えば2つのグループの平均卒業率が30%違ったとかであれば新しい教科書の成果っぽいですが、0.2%の違いとかだったら、偶然じゃないか?と思っちゃいますよね。ここで登場するのが統計学です。統計学の仮説検定という手法を用いることで、サンプル数とデータのばらつきを元に、どのくらいの可能性でその差が偶然であるかを算出することが可能になります。
そして、2つのグループの平均卒業率に差があり、かつその差が統計学的に認められれば(詳細は割愛しますが、統計学では有意という言い方をします)、「プロジェクト(新しい教科書)によって卒業率が改善した!」というエビデンスがある(因果関係がある)主張することができるわけです。
このように、2つの極めて類似したグループを作って比較することで、実施した場合と実施しない場合を同時に比較して、プロジェクトと効果の因果関係を特定するという手法全体をインパクト評価と呼んでおり、その手法の一つががRCTです。
インパクト評価・RCTの課題とは??
一見この話だけ聞くと、エビデンスを提示できる素晴らしい評価手法のように聞こえますよね。しかし、インパクト評価が全ての面で五項目評価をじめとする他の評価手法より優れているわけではありません。私が知っている範囲ですが、以下のような問題点が挙げられています。
・事前のデザインが全て(過去は振り返れない)
RCTは、事前にプロジェクトを実施するグループ(介入群、Treatment Group)と実施しないグループ(対照群、Control Group)をランダムに決めなくてはなりません。つまり、プロジェクトの実施中などに、後付けでRCTを実施することは不可能で、プロジェクト実施前に全て綿密にデザインすることが求められるため、柔軟性は非常に低いです。
・対照群(プロジェクトを実施しないグループ)を作る倫理的不公平感
今回の例で言うと、「あえて古い教科書を使うグループ」という明らかに不利に見えるグループを作らなくてはなりません。これは、不公平感という形で住民から不満が出る懸念がありますし、倫理的にどうなんだという指摘があります。
実際のプロジェクトでは、こういった不公平感が出ないように、古い教科書のグループにもプロジェクト終了後に新しい教科書で補講をするなど、様々な対策が取られています。
・プロジェクトの成功要因も複数ありうる
RCTによってプロジェクトと効果の因果関係が特定できたとします。しかし、まだそのプロジェクトのどの要素が効果に繋がったのかには疑問も残ります。例えば、新しい教科書のグループの方が良い卒業率を示したとしても、そのうち新しい教科書がよかったせいなのか、教えた先生がとびきり優秀だったせいなのか、などを切り分けるにはさらに複雑なデザインが必要になってきます。これは、屁理屈のようにも聞こえますが、実際は介入群(新しい教科書)の方が実施が難しいので、そちらに能力の高いスタッフを配置してしまうことは十分ありうることだと思います。
・お金と時間がかかる
RCTを行うには、事前の綿密なデザインとデータ収集、そしてプロジェクト開始後のモニタリングとデータ収集、と非常に手間と時間と実施能力が必要です。なので、コスト的にも大きなものになり、全てのプロジェクトに対してインパクト評価を実施するというのは現実的な案ではありません。
・実施できる機関が限られる
細かいデザインとランダム化、定期的なモニタリング等、非常に高度なマネジメントが求められますので、インパクト評価を実施するに能力がある実施機関を選定することも容易ではありません。そのため、そういったきちんとしたマネジメントができる団体が実施するから効果も出るのであって、この結果をもとに他地域・機関でも上手くいくとは言えないのではという指摘もあったりします。
・現場からの理解をえられにくい
ここまで読まれた皆さんですら、どれだけしっくり来ているかわかりませんが、この記事で書いたことを理解して初めてRCTの必要性と意義が理解できるわけです。そして現場のオペレーションへの負担も前述の通り、非常に大きなものになります。となると、実際に途上国の現場にこのアイディアを持ち込んだとしても、ほとんどの人は何のためにランダムにしているのか、何のために古い教科書を使う必要があるのか、何のために途中でグループを移ってはいけないのか、などを理解しないまま、インパクト評価を進めることになります。なので、現場(プロジェクト現場のみならず、開発機関の現地オフィスなども含めて)この難易度が高く難解なオペレーションを嫌がるケースが多く発生しています。
RCTができない場合
RCTはプロジェクトの効果の因果関係を測定する優れた評価手法ですが、上述のように、実際の現場では様々な問題が発生します。そのような場合はインパクト評価を諦めなくてはならないのでしょうか?ここでは、RCTのような実験デザインが難しい場合に用いられる、準実験デザインについても簡単に紹介しておきます(下図参照)。それぞれ客観性、コスト、難易度等でRCTよりは下がるのですが、倫理的に難しい場合などで、実際に現場で用いられることも多い評価手法です。

引用元:佐々木亮 「インパクト評価事例集 Ver 6.3」P59
インパクト評価に興味を持ったら
長々と読んでいただき、ありがとうございました。この記事を読んでインパクト評価に興味を持ったら次に読むべきものとして幾つか情報を挙げておきます。
・ノーベル経済学賞を受賞したバナジー氏のウェビナーの報告メモ

・バナジー氏らが運営するインパクト評価機関、J-PALに関する記事

・バナジー氏の書籍




コメント
[…] 今さら聞けないインパクト評価とRCTを解説してみました最近では国際開発業界でもよく聞かれるようになったインパクト評価およびランダム化比較試験(通称RCT)について、統計や経済 […]