

こんにちは!ICT4D Labメンバー兼PeaceTech部 部長の大石です。
PeaceTech部では先週から、「機械学習を使って難民の移動を予測する」プロジェクトを始めました。8月に要件定義、9月に予測モデルを立て、10月に成果を発表する挑戦的なスケジュールです。
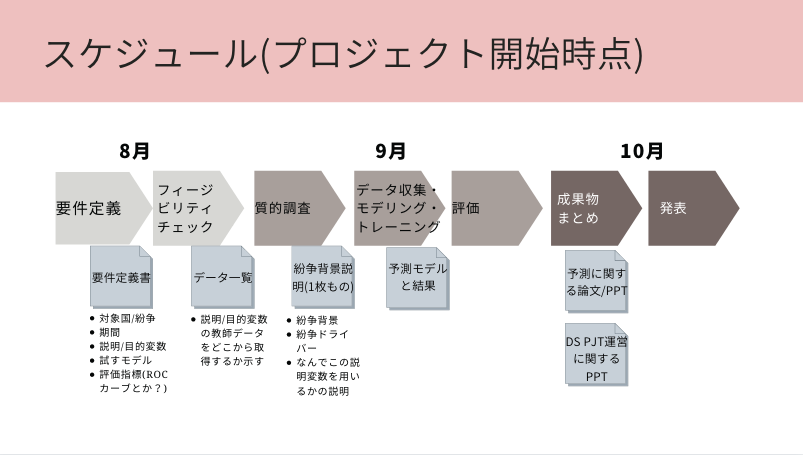
前回のブログで告知した通り、今回は要件定義フェーズの様子をお伝えします。
【ステップ3】要件定義フェーズの設計
今回のプロジェクトでは要件定義書作成までのステップを以下の様に設計しました。最終的に定義書にまとめるにあたり、どのデータを使うか・成功指標は何か・予測モデルは何を試すか等を整理します。
プロジェクトによっては要件定義書等を作成せずに、データサイエンティストがアジャイルで予測モデルの精度を高めていく事もあります。しかし本プロジェクトは「国際開発のエキスパートとデータサイエンティストの協業のコツを探る」事に重点を置いているので、両者共通の地図となる要件定義書をあえてキッチリ作成する事にしました。定義の過程で知識ギャップを認識・乗り越えるキッカケにもなりますし、背景知識の無いメンバーが途中参加しやすくなるというメリットもあります。

【ステップ4】予測対象の決定
前回のミーティングで「難民の移動を予測する」ところまでは合意しましたが、具体的な地域等は決めていませんでした。難民をテーマにした機械学習先行プロジェクト(Annie More プロジェクト、Xenophobiaトラッキングプロジェクト、ソマリアIDPプロジェクト 等)から知見を得つつ、部員とのディスカッションによって予測対象を以下のように決定しました。
「コンゴ民主共和国(イツリ州・北キブ州・南キブ州)で発生した戦闘・紛争によって、何日後に何人の難民が周辺国(ウガンダ・南スーダン・ルワンダ等から選定予定)に移動する」かを月次で予測する
上記予測が出来れば、ホストコミュニティや難民キャンプを支援する組織が事前に受け入れ体制を整える事ができます。また避難先選定に影響する変数とパターンを可視化できれば、学術的にも意味ある貢献ができると考えています。
実は予測対象を決定する前、私はどんな仮説を立て変数を設定するべきか、それら変数は実際にデータとして存在するかをとても気にしていました。「何を予測したいか」よりも「どう予測するか」を先に考え、予測出来そうな対象をテーマにしようとしていたのです。
そんな中、我らがChief Data Scientistのコメントは「仮説やデータ、モデルの作り方はどれも手段の一部。「何を予測するか」とか「良さの指標は何にするか」といったトピックの方が優先度が高く、国際開発に関するドメイン知識が最もクリティカルに効いてくる所」。
ただしい。。。!
ついついソリューションドリブンになりがちなAIプロジェクトですが、「何を予測するか=何を予測すると価値があるのか」を出発点にすべきだと、改めて考えさせられました。「ITを使って何かしたい」「AIを使って何かプロジェクトをやってみよ」。これらフレーズから出発するとどうしてもソリューションドリブン脳になってしいます。何が実現できると嬉しいのかという価値の設定にこそ、ドメインエキスパートの存在理由があるのかも知れません。
【学び】「どう実現するか」より「何を実現するか」。何が実現できると嬉しいのかという価値の設定にこそ、ドメインエキスパートの知見が必要!
ディスカッション録
Q.機械学習で難民の移動を予測した場合、予測精度はどうやって図るの?
A.基本的には過去データ(=教師データ)を2つに分けて、1つを学習用、もう1つを検証用に使う。学習用データを使って立てた予測モデルの予測結果がどのくらい合っているのか、検証用のデータを使って確かめる事が可能。
2つ目の方法として、未来を予測して、後々実際に確認してみるのもあり。例えば2020年9月1日までのデータを使って立てた予測モデルで、9月2日の出来事を予測し、9月2日になったら予測が合っていたか確認するイメージ。
Q.難民が何を理由にどこに移動するかは地域や背景によって大きく違う。どうやったらその違いを予測モデルに入れ込める?
A.本プロジェクトでは、難民発生の因果仮説を複数作成して、各仮説毎に予測精度を見てみるのがいいかも。ただ要注意!予測精度が高いからと言って、因果を証明した事にはならない。予測をゴールにするとき因果関係は無視した方がより多くの情報を使えて予測に有用な場合もある。「因果関係の知識を得る(因果モデルを推定する)ことは予測において役に立つか」は問うべきトピックであり、答えは出てない。
少し補足すると、通常の機械学習は「相関」に基づく予測であって「因果」に基づいている訳ではありません。例えば、とあるデータによると「台風の発生数」と「子供の学力低下」は相関があるそうです。果たして両者間に因果はあると言えるでしょうか?因果はないですよね。台風が子供の学力を下げているのではなく、台風がよく発生する「夏」は学校がお休みのため、子供の学力が低下するという構造だと想像がつくと思います。
純粋に学力低下率を予測するモデルの精度を上げたいのであれば、モデルに台風の発生数を入れるべきですが、この変数そのものは因果を説明しないという事がよく分かると思います。さらに言うと、予測に使った変数だけを信頼し予防的介入を設計するのは注意が必要です。仮に台風の発生数を減らしても子供の学力は向上しませんから。(このトピックは非常に奥が深いので後日、別ブログとしてまとめますね!)
今回私達が因果仮説を作ろうとしているのは、ドメインエキスパートの力を借りて知見を反映し、出来るだけ解釈可能な予測結果を得ようとしているからです。本当にただ高精度の予測モデルを作りたいならば、ありとあらゆる変数(例えば台風の発生数)をモデルに含める方が有用かも知れません。その場合、予測結果の解釈は難しくなりますが。
【学び】通常の機械学習で分かるのは相関であって因果ではない。予測モデルのみに基づいて予防的介入を設計するのは要注意!
次回
さて、予測対象が決まったら、次はプロジェクトキャンバス(こちらから拝借しました)の作成です。【ステップ4】で書いた通り、価値に重点を置いたフレームワークになっている事がよく分かると思います。
皆さんは、どんなキャンバスを描きますか?
===========
文責:大石彩夏
PeaceTechに興味ある方はこちら(Facebookの有志グループ)にJoin!

コメント
[…] 前回は、要件定義フェーズの1stステップとして、予測対象を決定しました。それに基づきプロジェクトキャンバスを作成し、仮説を設定するのが今回のステップです。 […]